خلاصه
حسابرسان دارای یک فرآیند کاملاً مشخص هستند که در آن حسابرسی را انجام می دهند. فرآیند کاوی جایگزین این رویکرد حسابرسی سنتی نمی شود. با این حال، حسابرسی نیاز به تغییرات و تلاش آگاهانه برای تطبیق فرآیند کاوی با روش کار فعلی دارد. در این مقاله، به تفصیل توضیح میدهیم که چگونه فرآیندکاوی در مراحل مختلف چرخه حسابرسی بر اساس یک پروژه قرار میگیرد. ما تغییراتی را که باید در فرآیند حسابرسی ایجاد شود و مزایا و چالشها را توضیح میدهیم.
دیوان محاسبات شهر وین یک موسسه حسابرسی عمومی مستقل وخودمختار است. این دیوان مؤسسات و نهادها در شهر وین را در مورد مدیریت مالی و ایمنی آنها حسابرسی می کند و با گزارش ها و توصیه های حسابرسی از کسانی که در پست های مسئولیتی در سیاست و مدیریت هستند حمایت می کند. دیوان محاسبات شهر وین در چارچوب کار حسابرسی خود، استفاده از بودجه عمومی وین را بررسی می کند. همچنین بر رعایت مقررات ایمنی برای محافظت از شهروندان وین نظارت می کند.
با این حال، منابع برای انجام این وظایف محدود است. برای تعیین اولویت های حسابرسی، دیوان محاسبات شهر وین از یک روش انتخاب برای حسابرسی ها در قالب تحلیل ریسک پیروی می کند. برای ممیزی های منتخب، تیم دیوان محاسبات شهر وین از رویه های حسابرسی مختلف استفاده می کند. به عنوان مثال از سال 2016 روش حسابرسی (کاوی) در چندین ممیزی استفاده شده است. در سال 2020، فرآیند خرید به پرداخت وینر Stadtwerke، یکی از بزرگترین گروه های زیرساخت اتریش، تجزیه و تحلیل شد. با استفاده از مثال Wiener Stadtwerke، این مقاله به تفصیل نشان میدهد که چگونه فرآیند کاوی برای انجام ممیزی مبتنی بر داده به کار گرفته شد. نتایج این حسابرسی در گزارش حسابرسی برای عموم در دسترس است. مقاله زیر بر روی روش فرآیند کاوی در زمینه حسابرسی تمرکز دارد و به تفصیل چگونگی استفاده از فرآیند کاوی در مراحل مختلف حسابرسی و چالشها و مزایایی را که تجربه کردیم، توضیح میدهد.
رویکرد حسابرسی مبتنی بر داده با فرآیند کاوی

استانداردهای حسابرسی پذیرفته شده بین المللی، کار حسابرسی دیوان حسابرسی شهر وین را هدایت می کند. در عین حال، هدف، بهبود بیشتر استانداردهای موجود با همکاری مؤسسات حسابرسی ملی و بینالمللی و تعامل در تبادل تجربیات است. ممیزی ها بر اساس فرآیند حسابرسی استاندارد انجام می شود (شکل پایین را ببینید).

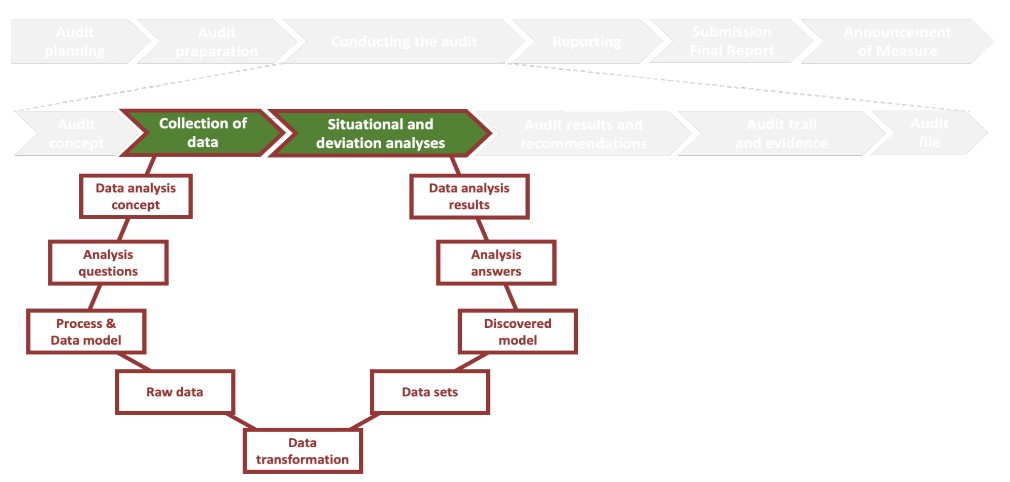
هر مرحله از فرآیند نشان داده شده در بالا شامل چندین کار است. شکل پایین وظایف مربوط به مرحله «Conducting the audit» را نشان می دهد: ابتدا یک مفهوم حسابرسی ایجاد می شود. سپس داده ها جمع آوری می شود. سپس از این داده ها برای انجام یک تحلیل موقعیتی و انحرافی استفاده می شود که نتایج و توصیه های حسابرسی از آن استخراج می شود. علاوه بر این، مسیر حسابرسی و شواهد مستند شده و پرونده حسابرسی ایجاد می شود.
هنگامی که از فرآیند کاوی در رویکرد حسابرسی عمومی خود استفاده می کنیم، باید روش کاری خود را تطبیق دهیم. به ویژه نحوه جمع آوری و تجزیه و تحلیل داده ها در فرآیند حسابرسی نسبت به سایر روش های حسابرسی تغییر می کند. برای گنجاندن فرآیند کاوی در مراحل «جمع آوری دادهها» و «تحلیل موقعیت و انحراف»، 9 مرحله نشان داده شده در شکل بعدی را دنبال کردیم. پیروی از این مدل به ما کمک زیادی کرد تا رویکردمان را هنگام استفاده از فرآیند کاوی در حسابرسی استاندارد کنیم. این نتایج ضروری برای «جمع آوری داده ها» و« تحلیل موقعیت و انحراف» را خلاصه می کند. در بخشهای بعدی، هر مرحله و هر یک از نتایج مدل نشاندادهشده در شکل بعدی را با جزئیات بیشتر توضیح میدهیم.

مرحله 1: مفهوم تجزیه و تحلیل داده ها
دیوان حسابرسی شهر وین از روش انتخاب حسابرسی مبتنی بر ریسک پیروی می کند. بنابراین، حسابرسی قبلاً در برنامه ریزی حسابرسی سالانه تعریف شده بود. مفهوم «تجزیه و تحلیل داده ها» دامنه حسابرسی را با جزئیات بیشتر تعیین می کند. این یک نمای کلی از طرف حسابرسی شده، فرآیند مورد علاقه، چارچوب فناوری اطلاعات و هدف اصلی حسابرسی را ارائه می دهد.
طرف حسابرسی شده – Wiener Stadtwerke – یکی از مهم ترین گروه های زیرساخت اتریش است.
حدود 15000 کارمند فعالیت های کسب و کار آن را می توان به شرح زیر دسته بندی کرد:
- انرژی (برق، گاز، گرمایش، سرمایش)
- تولید
- توزیع
- عملیات شبکه
- حمل و نقل عمومی (مترو، تراموا، اتوبوس)
- مدیریت و برنامه ریزی ترافیک
- عملیات
- بازار یابی
- توزیع
- مراسم خاکسپاری
- گورستان ها
- مهد کودک قبرستان
- سنگ تراشی
- پارکینگ
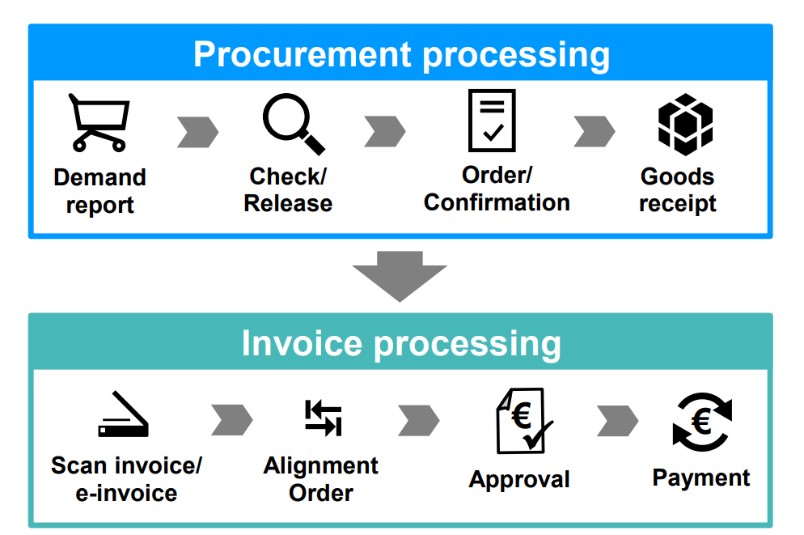
مجموع دارایی های Wiener Stadtwerke در 31 دسامبر 2020 تقریباً 13900 میلیون یورو بود. گروه Wiener Stadtwerke 100٪ متعلق به شهر وین است. ما با تشریح دامنه کلی فرآیند، فرآیند مورد علاقه را با جزئیات بیشتری تعریف کردیم. همانطور که ما برای حسابرسی فرآیند «خرید به پرداخت برنامه ریزی کردیم، این فرآیند را همانطور که در شکل 4 نشان داده شده است، تعیین کردیم. دامنه فرآیند حسابرسی شده شامل خرید و پردازش فاکتور بود که با گزارش تقاضا شروع می شود و با پرداخت فاکتور مربوطه پایان می یابد.
این دامنه فرآیند کلی بعداً به عنوان یک نقطه مرجع برای بررسیهای بیشتر مورد استفاده قرار گرفت و اولین تصور را از نقاط شروع و پایان فرآیند مورد نظر ارائه داد. بازه زمانی حسابرسی سال 2019 تعیین شد. به طور دقیق تر، ما تمام سفارش هایی را که بین 01 ژانویه 2019 و 31 دسامبر 2019 ارسال شده بودند در نظر گرفتیم. ما زیرساخت فناوری اطلاعات دیوان محاسبات شهر وین و طرف حسابرسی شده را بررسی کردیم تا ایده ای در مورد نوع داده ها و ابزارهایی که برای پردازش و تجزیه و تحلیل این داده ها در دسترس هستند به دست آوریم. از تحقیقات اولیه ما، میدانستیم که طرف حسابرسی شده از SAP برای مدیریت فرآیند خرید-پرداخت استفاده میکند. ما انتظار داشتیم که پس از اینکه دادهها را از SAPخروجی گرفتیم ، باید آنها را تغییر دهیم.
به عنوان یک ابزار ETL برای انجام این تبدیلها، ما پلتفرم KNIME Analytics [3] را انتخاب کردیم زیرا قبلاً از این نرمافزار برای تبدیل دادهها در پروژههای فرآیند کاوی قبلی استفاده کردهایم و به نتایج خوبی دست یافتهایم.
هدف اولیه حسابرسی انجام ممیزی انطباق بود. ما میخواستیم فرآیند خرید تا پرداخت WienerStadtwerke را در مورد منظم بودن و انطباق آن با شرایط چارچوب خاص سازمان تجزیه و تحلیل کنیم.
با توجه به این هدف اصلی حسابرسی، ما برنامه ریزی کردیم تا به جنبه هایی مانند کامل بودن فرآیند، تفکیک وظایف، پایبندی به اصل Four-eyes و اثربخشی سیستم کنترل داخلی بپردازیم. علاوه بر این، ما میخواستیم زمان هدایت و وقوع گلوگاهها را از منظر عملکرد در نظر بگیریم. سوالات تجربه کاربر خارج از محدوده این ممیزی بود. پس از تعریف چارچوب کلی و هدف اولیه حسابرسی، زمان آن فرا رسید که حوزه های تمرکز حسابرسی را با جزئیات بیشتری مشخص کنیم. بنابراین، در گام بعدی، سؤالات تحلیل مشخصی را که میخواستیم در تحلیل فرآیند کاوی خود به آنها پاسخ دهیم، شناسایی کردیم.
مرحله 2: تجزیه و تحلیل سوالات
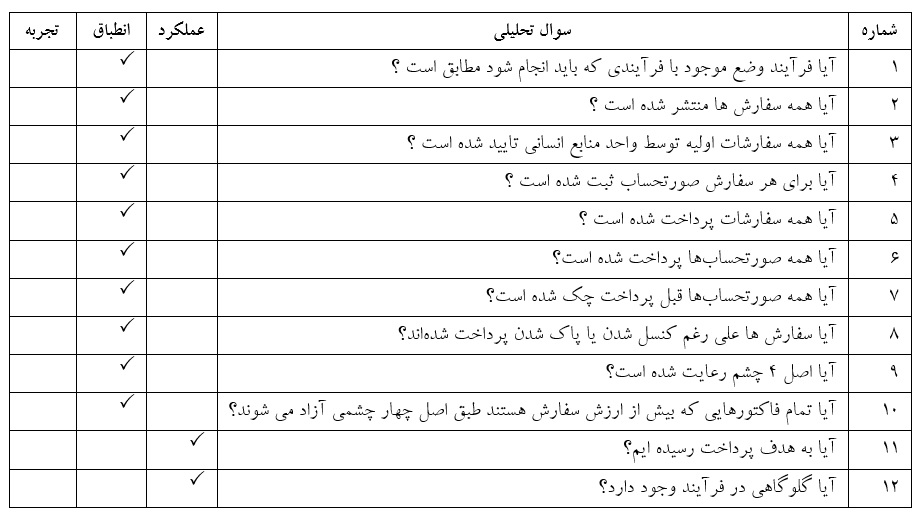
ما 12 سوال تحلیلی زیر را تعریف کردیم (جدول 1 را ببینید). همانطور که در جدول 1 نشان داده شده است، بیشتر سؤالات مربوط به مسائل مربوط به انطباق (هدف اصلی حسابرسی ما) هستند، تنها دو سؤال مربوط به عملکرد هستند و هیچ کدام در مورد تجربه کاربر نیستند. علاوه بر فرمول بندی سوالات تحلیل کلی، سعی کردیم تا حد امکان دقیق آنها را تعریف کرده و قابل اندازه گیری کنیم. بنابراین، ما متریک، مقدار هدف، دامنه فرآیند مورد نظر و عوامل تأثیرگذار را برای هر سؤال تجزیه و تحلیل مشخص کردیم.
جدول 2 نشان می دهد که چگونه سؤال تحلیل شماره 2 را با تعریف این جنبه ها عینی تر کردیم. وقتی می خواهیم به این سوال پاسخ دهیم که آیا همه سفارشات ترخیص می شوند؟ در ابتدا ساده به نظر می رسد، اما ایده خوبی است که بیشتر در مورد اینکه چگونه می توانیم دقیقاً پاسخ این سؤال را اندازه گیری کنیم، فکر کنیم. ما انتظار داشتیم که ترخیص سفارش در سیستم اطلاعاتی ثبت شود. بنابراین، ما حضور فعالیت ترخیص را به عنوان یک معیار انتخاب کردیم.
علاوه بر این، ما فرض کردیم که تمام سفارشات باید بدون استثنا ترخیص شوند. بنابراین، ما مقدار هدف را روی 100٪ تنظیم می کنیم، به این معنی که یک فعالیت ترخیص باید برای هر سفارش مستند شود. سپس، محدوده فرآیند را تعریف کردیم تا نشان دهیم کدام بخش از فرآیند خرید تا پرداخت برای یافتن اطلاعات مورد نیاز برای پاسخ به سؤال تحلیل مربوط است. برای سوال شماره 2، دامنه فرآیند شامل تمام فعالیت های مربوط به مرحله ترخیص در سیستم اطلاعاتی است. در نهایت، ما همچنین عوامل مؤثری را که باید در حین انجام تجزیه و تحلیل داده ها و تفسیر نتایج در نظر بگیریم، جمع آوری کردیم. در مورد ترخیص سفارش، ما فرض کردیم که اصل Four-eyes ممکن است باشد.
بنابراین ما محدودیت مقادیر را به عنوان یک عامل تأثیرگذار تعریف کردیم که باید برای تجزیه و تحلیل بعدی در نظر گرفته شود. ما تعاریف دقیقی را برای تمام سؤالات تحلیلی به روشی مشابه همانطور که برای سؤال شماره 2 در بالا نشان داده شد، مشخص کردیم. از آنجایی که ما سؤالات تحلیلی را در مراحل اولیه پروژه فرآیند کاوی تعریف کردیم، باید مفروضات خاصی را انجام دهیم، به ویژه در مورد متریک و عوامل تأثیرگذار. ما این سؤالات تحلیلی را چندین بار در مراحل بعدی پروژه تطبیق دادیم زیرا بینش بیشتری نسبت به فرآیند و داده ها به دست می آوردیم. با این وجود، تعریف سوالات تحلیلی در این مرحله اولیه پروژه بسیار مفید بود. این به ما کمک کرد تا دید کلی خوبی از داده های مورد نیاز خود داشته باشیم. در نتیجه، میتوانیم خطر فراموشی برخی جنبهها یا فیلدهای داده را در حین استخراج داده کاهش دهیم.
مرحله 3: مدل فرآیند و داده
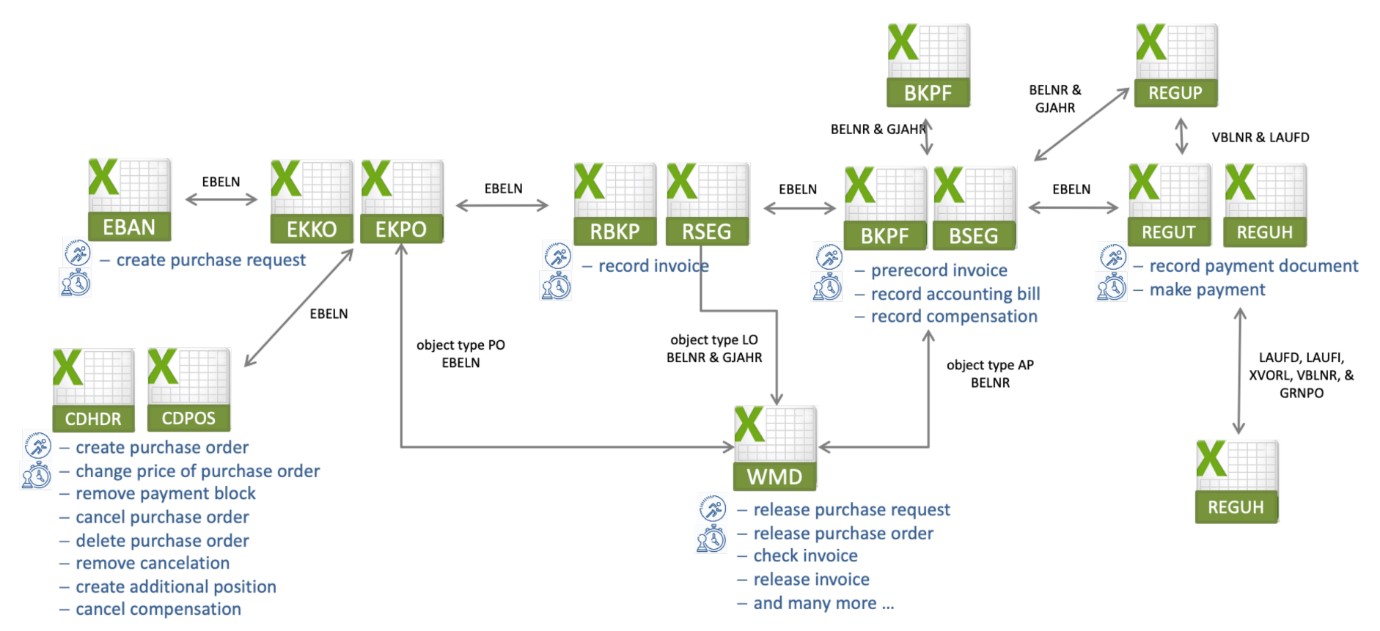
با نگاهی دقیق تر به فرآیند خرید تا پرداخت، واضح بود که بسیار پیچیده است. ما شرح مفصلی از فرآیند را از طرف حسابرسی شده دریافت کرده بودیم و تصمیم گرفتیم که فرآیند را ساده کنیم و از منظری انبوه به آن نگاه کنیم تا پیچیدگی را مدیریت کنیم. فرآیند مرجع سطح بالایی که ما تعریف کردیم فقط شامل مراحلی بود که برای یافتن پاسخ به سؤالات تحلیلی که در مرحله قبل توضیح داده شد ضروری بودند. ما انتظار داشتیم که مقادیر قابل توجهی داده برای این فرآیند در سیستم اطلاعاتی تولید شود. بر اساس فرآیند مرجع سطح بالا، ما سعی کردیم فیلدهای داده ضروری را که در حین انجام فرآیند پر شده اند شناسایی کنیم. فرآیند خرید تا پرداخت عمدتاً با استفاده از SAP اجرا شده بود. برای هر مرحله فرآیند، ما به دنبال جدول پایگاه داده مربوطه گشتیم و مدل فرآیند را با این اطلاعات غنی کردیم. برای مثال، دادههای «ایجاد درخواست خرید» را میتوان در جدول EBAN در SAP قرار داد (شکل زیر را ببینید).
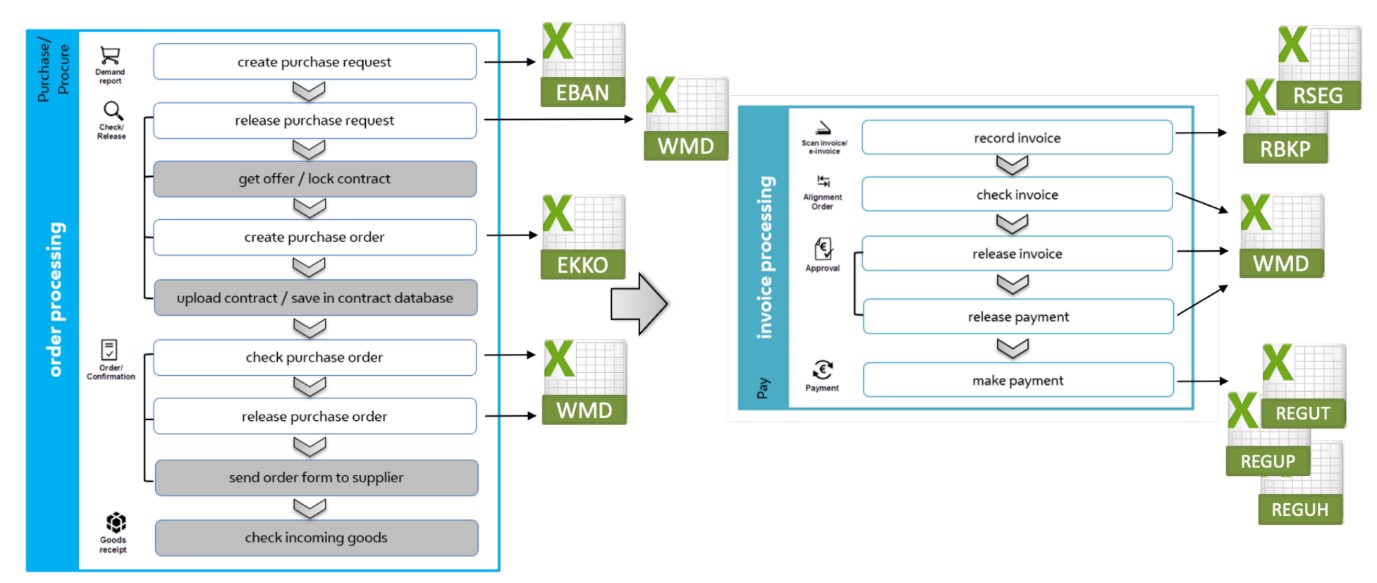
هنگام ایجاد مدل فرآیند و داده، متوجه شدیم که تمام مراحل فرآیند مرجع سطح بالا در SAP انجام نشده است. به عنوان مثال، ما متوجه شدیم که گردش کار تایید و انتشار با یک افزونه SAP به نام WMD xSuite feeder انجام شده است. از آنجایی که مراحل تایید و انتشار برای ممیزی انطباق ضروری بود، ما این جداول دادهها را در مدل داده و استخراج دادههای بعدی گنجاندهایم. سایر مراحل مانند دریافت پیشنهاد، قفل کردن قرارداد، ارسال فرم سفارش به تامین کننده و بررسی کالاهای دریافتی نه در SAP و نه با فیدر WMD xSuite انجام نشده است. این مراحل (به رنگ خاکستری در شکل 5) به صورت دستی یا از طریق ایمیل انجام شد. به دلیل عدم دسترسی به داده، این مراحل را از تجزیه و تحلیل فرآیند کاوی خود حذف کردیم. پس از تعریف فرآیند و مدل داده، دید کلی خوبی از دادههای موجود و جایی که میتوانیم دادهها را پیدا کنیم، داشتیم. بنابراین در مرحله بعد، داده های خام را برای پردازش بیشتر استخراج کردیم.
مرحله 4: داده های خام
داده های تجزیه و تحلیل فرآیند کاوی ما در دو سیستم مختلف ذخیره شد: SAP و فیدر WMD xSuite. زمانی که مدل داده را مشخص کردیم، جداول داده ای را که باید از این سیستم ها استخراج شوند، شناسایی کرده بودیم. ما هیچ دسترسی مستقیمی به سیستم های اطلاعاتی Wiener Stadtwerke نداشتیم. بنابراین، طرف حسابرسی شده جداول داده را برای ما استخراج کرد و داده های خام را در فایل های CSV ارائه کرد. از مدل داده، ما قبلاً می دانستیم که زمان برای هر فعالیت در کدام جداول قرار دارد. برای مثال، میدانستیم که زمان «ایجاد درخواست خرید» را میتوان در جدول EBAN یافت. زمانی فعالیت «درخواست خرید آزاد» را میتوان در جدول WMD و غیره یافت. با این حال، از آنجایی که دادههای خام در چندین فایل CSV توزیع میشد، ما همچنین نیاز داشتیم که اتصالات بین جداول دادههای جداگانه را پیدا کنیم تا بتوانیم فایلها را در یکی ادغام کنیم (شکل 6 را در صفحه زیر برای ارتباط بین جداول ببینید). برای هر جدول، ما شناسایی کردیم که کدام اطلاعات می تواند به عنوان زمان برای یک فعالیت، منابع و سایر ویژگی های مربوط به فعالیت یا مورد استفاده شود. بر اساس دانش فیلدهای داده مربوطه برای زمان فعالیت، ویژگیها و منابع، و با این درک از ارتباطات بین جداول دادههای خام، اکنون مبنایی برای ساخت گزارش رویداد ما شد.
مرحله 5: تغییر شکل داده ها
هدف گام بعدی این بود که داده های خام را در قالبی بیاوریم که بتوانیم در نرم افزار فرآیند کاوی بارگذاری کنیم. ما اطلاعات مربوطه را از فایل های داده خام فیلتر کردیم و جداول داده را بر اساس اتصالات تعریف شده قبلی پیوند دادیم. دادههای خروجی بهعنوان یک گزارش رویداد، با شناسه منحصربهفرد بهعنوان شناسه مورد (Case ID)، نامهای فعالیت، زمان ، منابع و ویژگیهای هر رویداد صورتبندی شدند. ما تبدیل داده ها را با استفاده از نرم افزار منبع باز KNIME انجام دادیم. برای اعتبارسنجی دادههای تبدیلشده، هر زمان که تغییراتی را در گردش کار تبدیل دادهها اعمال کردیم، با سیستم تولیدی بررسی متقابل انجام دادیم. این مراحل اعتبارسنجی پتانسیل کاملی برای بهبود نشان داد و ما چندین بار جریان کار را تطبیق دادیم تا اینکه دادههای خروجی در نهایت دادههای سیستم تولیدی را نشان داد (شکل 7 را در صفحه بعد ببینید). تبدیل داده ها زمان برترین مرحله در پروژه فرآیند کاوی بود. یکی از عوامل این بود که ما دسترسی مستقیم به سیستم تولیدی نداشتیم. بنابراین، طرف حسابرسی شده باید از فرآیند اعتبارسنجی داده ها پشتیبانی می کرد و به بررسی متقاطع کمک می کرد. این امر منجر به زمان انتظار و تاخیر در پروژه شد.
عامل دیگر این بود که ما در ابتدا روابط 1:n و n:m را در هنگام ردیابی شناسه های مورد (Case ID) به درستی در نظر نگرفتیم. به عنوان مثال، یک سفارش می تواند منجر به چندین فاکتور و پرداخت شود. علاوه بر این، یک فاکتور می تواند به چندین سفارش رسیدگی کند. یک پرداخت می تواند بیش از یک فاکتور را پوشش دهد و غیره. این روابط چند به چند [4] باید به اندازه کافی در طول تغییر شکل داده ها مدیریت می شد. پس از چندین انطباق با گردش کار تغییر شکل ، ما تمام مراحل اعتبار سنجی را پشت سر گذاشتیم و مجموعه داده ای تولید کردیم که مطمئن بودیم با آن کار می کنیم.
مرحله 6: مجموعه داده ها
گردش کار تغییر شکل داده مجموعه داده ای را ایجاد کرد که می توانستیم برای تجزیه و تحلیل فرآیند کاوی خود از آن استفاده کنیم. بر اساس داده ها، بین 01 ژانویه 2019 تا 31 دسامبر 2019، در مجموع 2550 سفارش با ارزش سفارش تقریباً 21 میلیون یورو پردازش شد. در ابتدا، شماره سفارش را به عنوان شناسه پرونده خود انتخاب کرده بودیم. بنابراین، همه موارد از منظر سفارش تجزیه و تحلیل شدند (شکل پایین را ببینید).
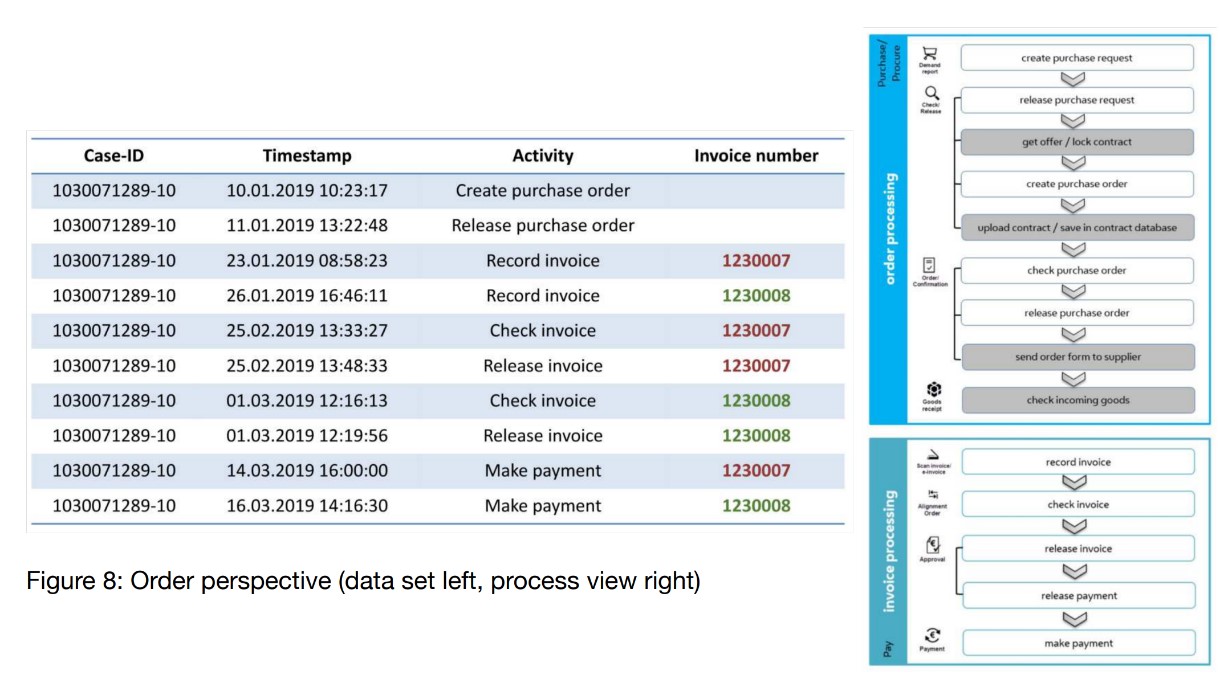
با این حال، در طول تجزیه و تحلیل، مشخص شد که به دلیل رابطه 1:n بین سفارش ها و فاکتورها، ما نمی توانیم به تمام سوالات تحلیلی خود در مورد پردازش فاکتور با این مجموعه داده پاسخ دهیم. به عنوان مثال، در شکل 8 می توان مشاهده کرد که دو فاکتور (فاکتور 1230007 و فاکتور 1230008) با سفارش 1030071289-10 مرتبط هستند. دو رویداد برای فعالیت «بررسی فاکتور» و «پرداخت» (یکی برای هر فاکتور) وجود دارد. این امر پاسخ به سؤالاتی مانند سؤال تجزیه و تحلیل شماره 7 را پیچیده می کند («آیا همه فاکتورها قبل از پرداخت بررسی شده اند؟»). بنابراین، ما تصمیم گرفتیم مجموعه داده دوم را با تمرکز بر چشم انداز فاکتور تولید کنیم. این با ترکیب شماره سفارش و فاکتور در یک شناسه پرونده جدید به دست آمد. دامنه این مجموعه داده دوم کوچکتر است (فقط صورتحساب و پرداخت). مزیت این است که فعالیتهای مربوط به فاکتور 1230007 و فعالیتهای مربوط به فاکتور 1230008 اکنون در حالت خاص خود ظاهر میشوند و میتوان آنها را به طور جداگانه تجزیه و تحلیل کرد.
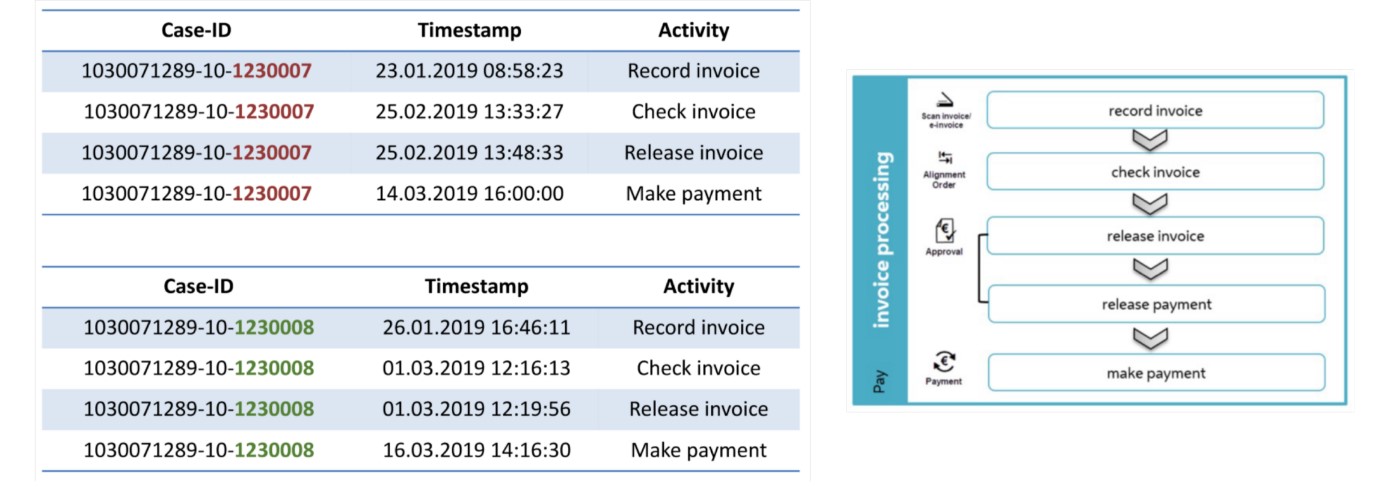
بر اساس این دو مجموعه داده – یکی از منظر سفارش و دیگری از منظر صورتحساب – اکنون میتوانیم به سؤالات تحلیلی خود پاسخ دهیم.
مرحله 7: مدل کشف شده
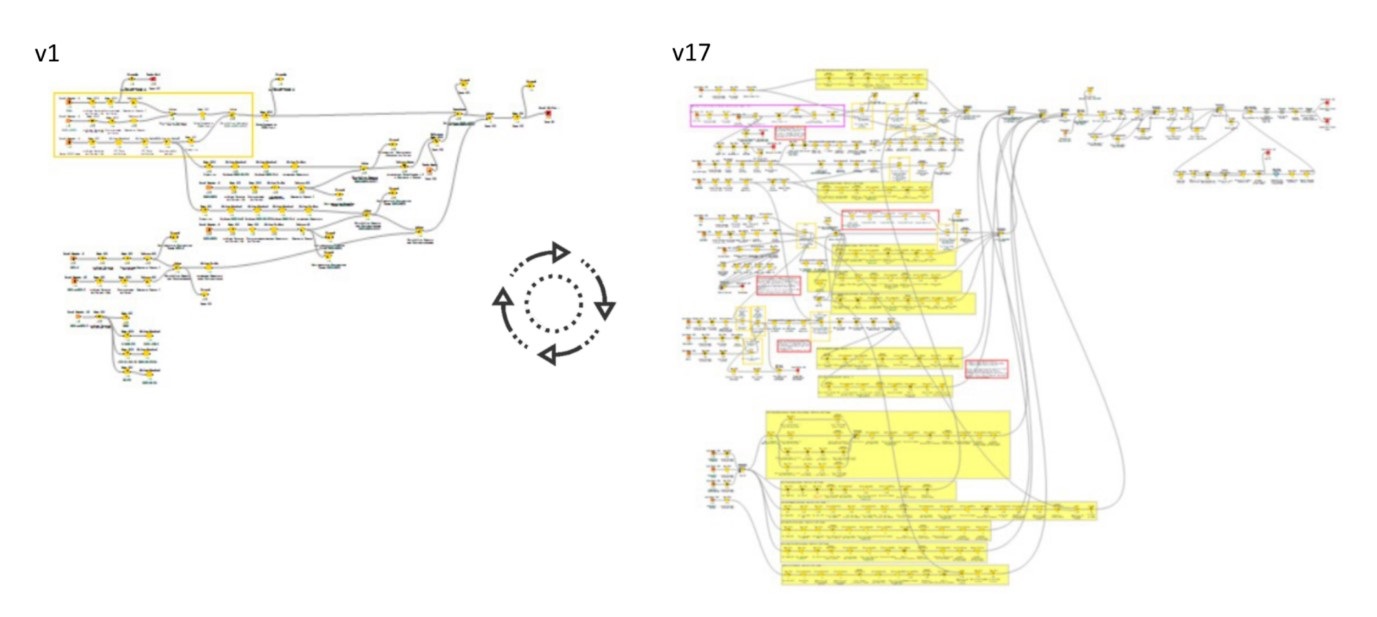
هنگامی که ما به مجموعه داده های تبدیل شده خود دسترسی پیدا کردیم، داده ها را در نرم افزار فرآیند کاوی Disco [5] بارگذاری کردیم و اولین تصور را از پیچیدگی فرآیند دریافت کردیم. اگرچه ما از ابتدا با روشهای سادهسازی کار کرده بودیم و بر روی فعالیتهای فرآیند مرجع سطح بالا نشاندادهشده در شکل 5 برای شناسایی جداول دادههای مرتبط متمرکز بودیم، نقشه فرآیند هنوز بسیار پیچیده بود. شکل 10 مدل فرآیندی کشف شده را از منظر سفارش نشان می دهد.

به دلیل پیچیدگی بالا، ما استراتژیهای سادهسازی بیشتری را برای فعال کردن یک تحلیل اکتشافی و مقایسه مسیرهای فرآیند واقعی و فرآیند مرجع اعمال کردیم. اولاً، با گنجاندن بیشتر فیلدهای زمان که میتوانستیم پیدا کنیم، تعداد زیادی فعالیت از فایلهای داده خام به دست آورده بودیم. از جمله این فعالیت ها مراحل فرآیند اداری بود که خارج از فرآیند مرجع ما بود. ما تعداد فعالیتها را تنها با حفظ آن دسته از مراحل فرآیند کاهش دادیم که میتوانستیم مستقیماً به فرآیند مرجع سطح بالا ترسیم کنیم (روش سادهسازی Milestone [6]).
این امر تعداد فعالیتها را از بیش از 100 به تقریباً 50 کاهش داد. توجه داشته باشید که دادههای سیستم فناوری اطلاعات هنوز جزئیتر از فرآیند سطح بالا بود. به عنوان مثال، یک سفارش خرید می تواند در سطوح مختلف بررسی، رد و منتشر شود (شکل 11 را ببینید). ثانیا، هنوز تنوع زیادی در مورد مسیرهای فرآیند وجود دارد. بنابراین تصمیم گرفتیم داده ها را در چهار گروه خوشه بندی کنیم (روش ساده سازی متغیر معنایی [7]). این چهار گروه عبارت بودند از:
1) موارد لغو شده،
(2) موارد بدون فاکتور،
(3) موارد با یک فاکتور،
(4) موارد با فاکتورهای متعدد.
با نگاه کردن به هر بخش داده به طور جداگانه، تعداد انواع فرآیند کاهش بیشتری یافت.
ادامه دارد ….